Despite recent progress in generative adversarial network (GAN)-based vocoders, where the model generates raw waveform conditioned on acoustic features, it is challenging to synthesize high-fidelity audio for numerous speakers across various recording environments.
In this work, we present BigVGAN, a universal vocoder that generalizes well for various out-of-distribution scenarios without fine-tuning.
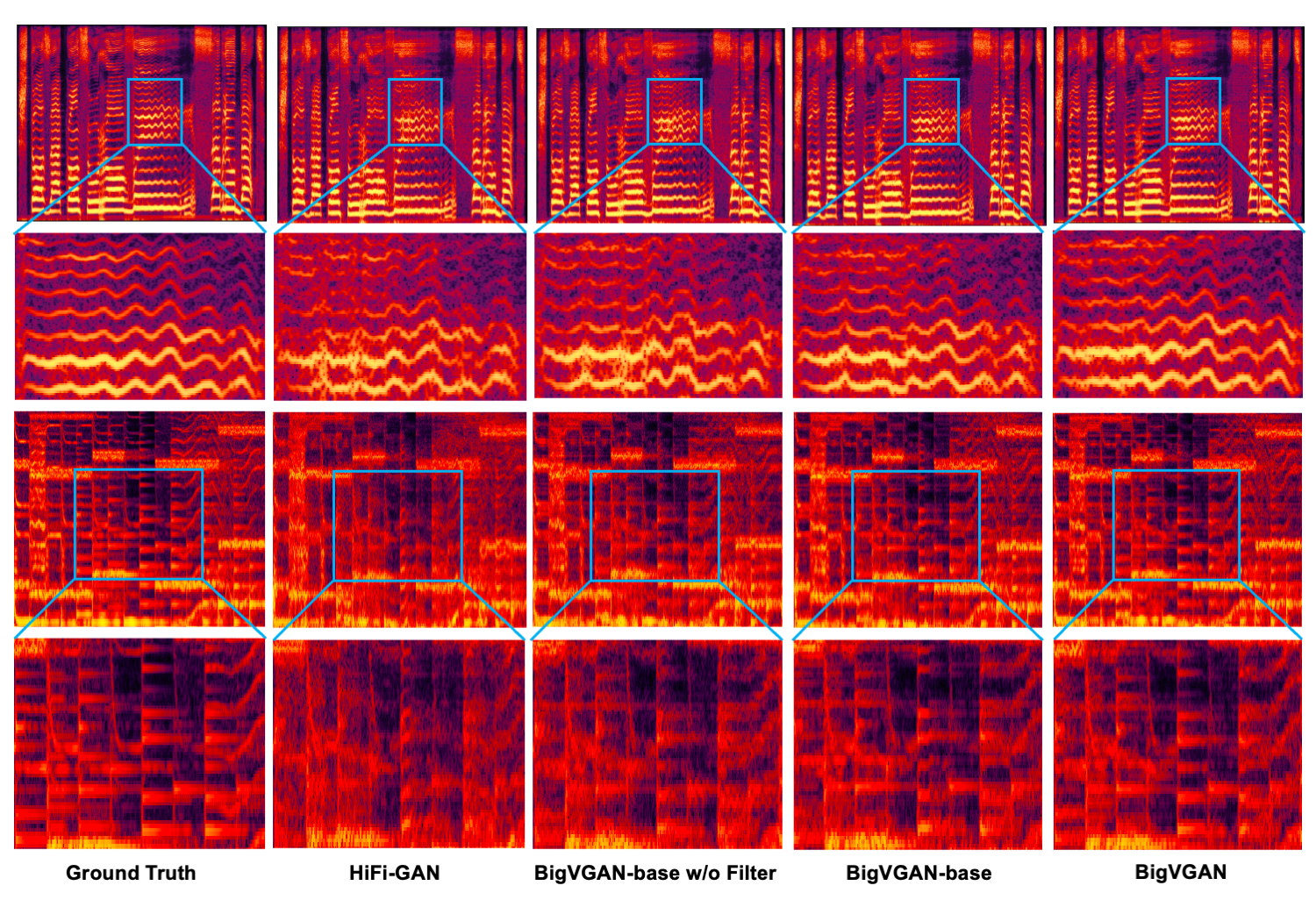
We introduce periodic activation function and anti-aliased representation into the GAN generator, which brings the desired inductive bias for audio synthesis and significantly improves audio quality.
In addition, we train our GAN vocoder at the largest scale up to 112M parameters, which is unprecedented in the literature. We identify and address the failure modes in large-scale GAN training for audio, while maintaining high-fidelity output without over-regularization.
Our BigVGAN, trained only on clean speech (LibriTTS), achieves the state-of-the-art performance for various zero-shot (out-of-distribution) conditions, including unseen speakers, languages, recording environments, singing voices, music, and instrumental audio.
BigVGAN, trained only on LibriTTS, exhibits strong zero-shot performance and robustness to out-of-distribution scenarios.
BigVGAN is capable of synthesizing non-speech vocalizations or audios, such as laughter, singing, and any types of in-the-wild audio from YouTube clips.
Ground-Truth
HiFi-GAN (V1)
UnivNet-c32 (train-clean-360)
BigVGAN
BigVGAN-base
SC-WaveRNN
Visualization
The image below demonstrates spectrogram visualization of BigVGAN for out-of-distribution audio, with a zoomed-in view of high-frequency harmonic components.
Top: a singing voice. Bottom: an instrumental audio.
Out-of-distribution robustness: MUSDB18-HQ
BigVGAN, trained only on LibriTTS, exhibits strong zero-shot performance and robustness to out-of-distribution scenarios.
BigVGAN is capable of synthesizing a wide range of singing voice, music, and instrumental audio which are unseen during training.
Types
Ground-Truth
HiFi-GAN (V1)
UnivNet-c32 (train-clean-360)
Others (Guitars)
Vocal
Drums
Bass
Mixture
Mixture
Types
BigVGAN
BigVGAN-base
SC-WaveRNN
Others (Guitars)
Vocal
Drums
Bass
Mixture
Mixture
LibriTTS test-clean samples from unseen speakers
Ground-Truth
HiFi-GAN (V1)
UnivNet-c32 (train-clean-360)
BigVGAN
BigVGAN-base
SC-WaveRNN
LibriTTS test-other samples from unseen speakers
Ground-Truth
HiFi-GAN (V1)
UnivNet-c32 (train-clean-360)
BigVGAN
BigVGAN-base
SC-WaveRNN
Unseen languages and recording environments
Ground-Truth
HiFi-GAN (V1)
UnivNet-c32 (train-clean-360)
BigVGAN
BigVGAN-base
SC-WaveRNN
Ablation study: methods
Ablation models based on BigVGAN-base by disabling anti-aliased filter or snake activation function.
BigVGAN-base
(w/o filter)
(w/o filter&snake)
Ablation study: model capacity
Ablation model of BigVGAN (HiFi-GAN (112M)), where the model capacity is maximized to the same 112M parameters and the architectural improvements are disabled.
Simply increasing the model size is not sufficient to achieve BigVGAN's robustness to out-of-distribution data. HiFi-GAN (112M) exhibits similar types of artifact to the original HiFi-GAN (V1).
Ground-Truth
HiFi-GAN (112M)
BigVGAN (112M)
Bonus: extreme out-of-distribution examples
WARNING: SAMPLES MAY HAVE EXTREMELY LOUD VOLUME WITH CHAOTIC SOUND!
A robustness "stress test" of BigVGAN. BigVGAN is robust to extreme out-of-distribution samples, such as audio effects and electronic music with loud drums and complex synthesizers, which has not been possible in the literature.